Yeah, regarding the missing and large icons, user-generated content is messy…
One thing to keep in mind is we have both browsers and the Android client generating the traffic. The Android client is probably more traffic, and doesn’t behave like a browser. For example, it doesn’t do anything with HTTP Headers except for ETag. But we can still get much improved caching for browsers, and that’s where the slowness is most felt anyway. The Android client does most network operations async.
About the caching settings on the webserver, my guess is that the settings for the icons folders will be the only one that makes a noticable difference. The upside is that those icon files have permanent, unique filenames. So we could set the caching of those files to 6 months, and that would be safe. The hard part is that Apache does not allow per-folder caching settings in the .htaccess file, only per-file.
We could add a rule in the webserver config files to set that caching, ie.:
If I understand correctly, you cannot edit the repo server configuration so you are restricted to using .htaccess files? Can you put another .htaccess in /repo/icons-640/ and add the headers there?
Sorry its kinda big, but it illustrates the problem.
Is that the buildserver’s job to extract the icons from the source archive? Maybe that could be changed to be more consistent and always include a version number. It would be even better if it resized images back if they are too large.
ps:
Going from 58076 to 6052 bytes, that is nearly 10x reduction.
Resizing would also be better for old smartphones and slow connections.
The biggest question is maintainability: right now, we’re already setup to manage .htaccess files, but not really setup to manage the Apache config files as well. That’s why .htaccess is preferred. But it sounds like we should have the icons caching setttings in the Apache config, I think its worth the added maintenance load.
There already are various versions of icons available, for example:
I think we’ll have better results if we improve the caching of the hi-res icons, rather than force lower res icons. Mobile screens are hi-DPI, so 512x512 is not actually that big.
Better caching is definitely needed, but imho we should do both, and more. Just one change is not enough to fix the current performance problems and make it future proof. A multilevel approach could be:
Improve the data caching. (unique filenames, cache headers)
Reduce the size of data. (reduce image sizes)
Improve the proxy server performance (move to nginx, http2, …)
Hdpi is good but do we really need 2.67 times xxxhdpi? In terms of surface area that is 7.1x. Icons are displayed at 48 pixels on the website. In the app it varies, some are twice as big as others and they will benefit from higher resolution but I think 192x192 is good enough. I noticed there is not that much saving going from 192 to 96, but from 512 to 192 is substantial, especially when you optimize the image with pngquant and zopflipng. Some work on the icon bit needs to be done anyway because only half the icons have unique filenames at the moment.
Screenshots also consume a lot of data. Most of the time I do not need to see them while browsing packages, just reading the description. An option could be to make the user click a button or something to load them, if they are not in the user’s cache already.
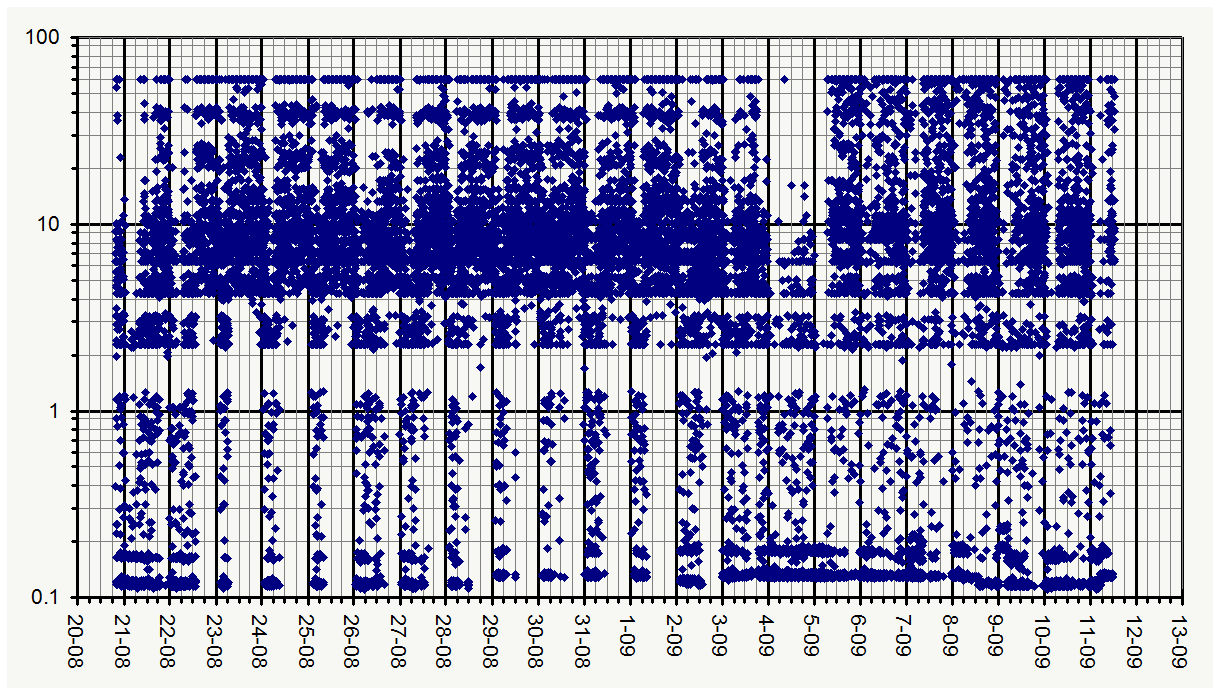
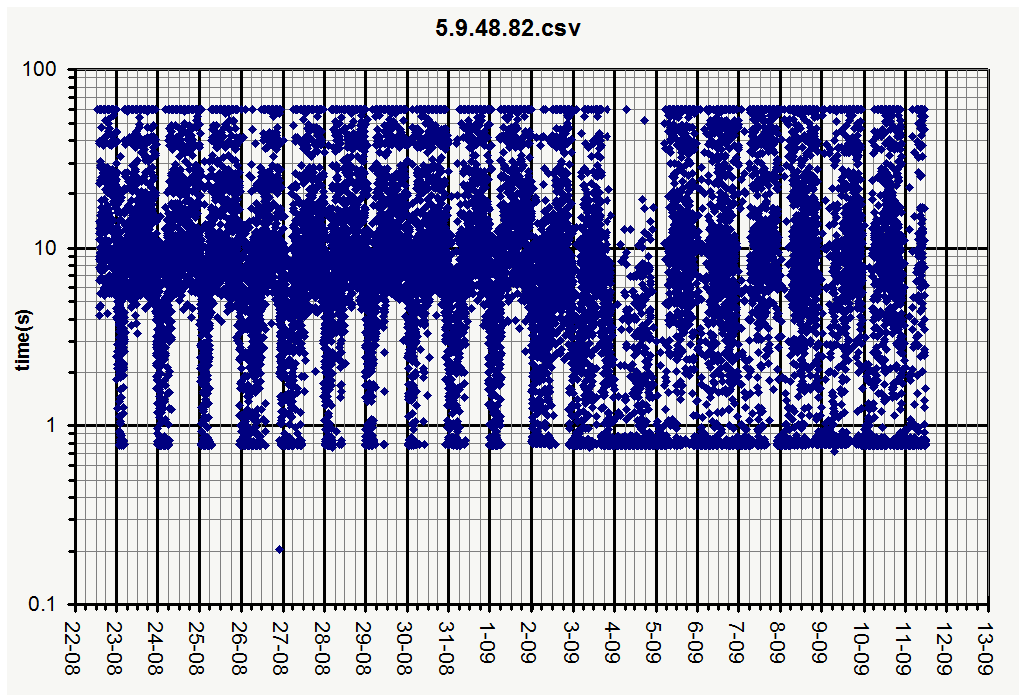
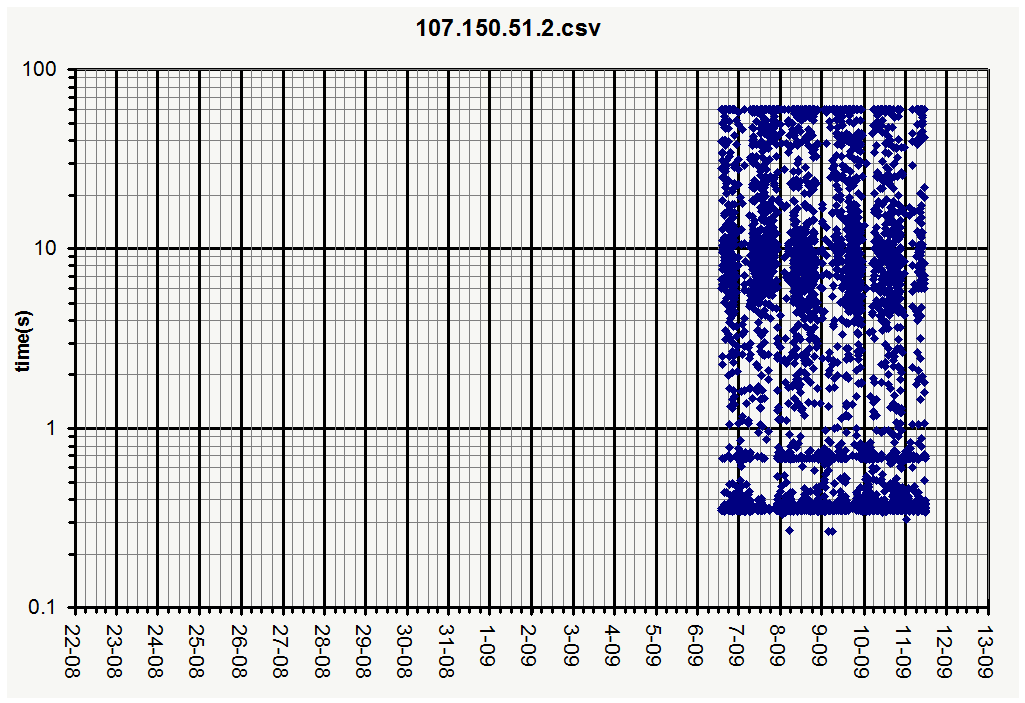
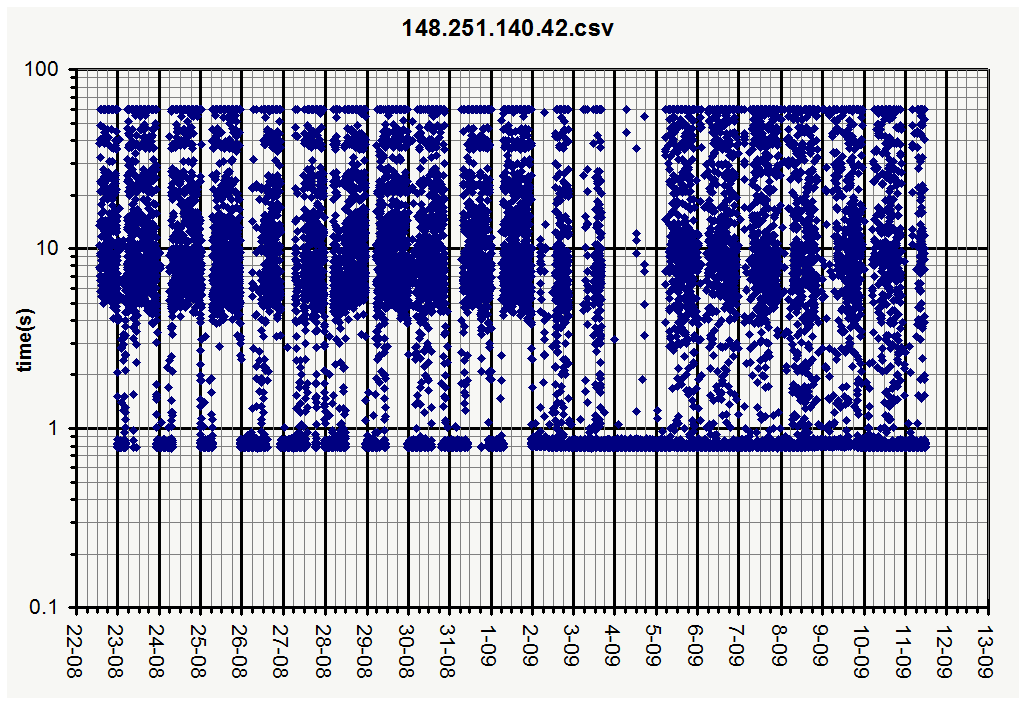
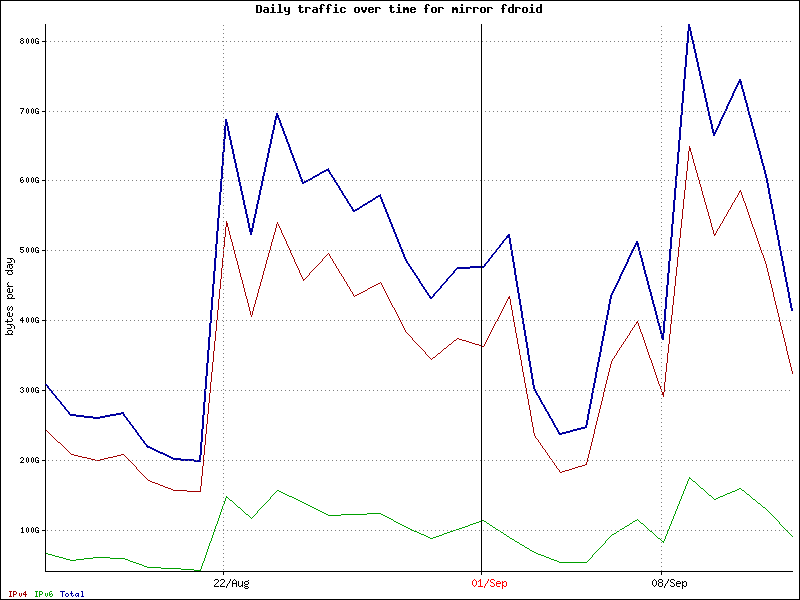
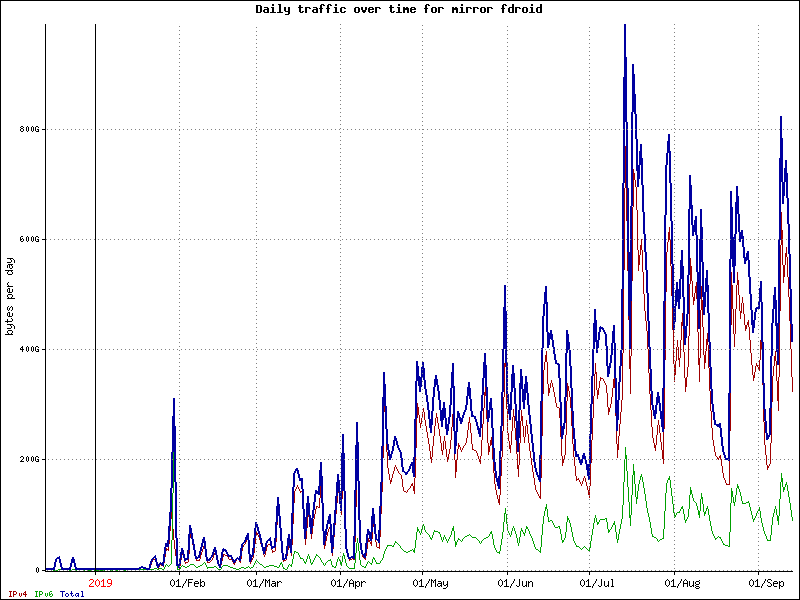
Nice! The new graph shows a nice improvement! I agree, we do need to improve many aspects of how the site is working. I posted the data files from my monitor, that includes the new cache:
especially when you optimize the image with pngquant and zopflipng.
PNG crunching is part of the standard Android build server, so the embedded icons are already crunched. The screenshots are less likely, since that would need to be manually done.
Screenshots also consume a lot of data. Most of the time I do not need to see them while browsing packages, just reading the description. An option could be to make the user click a button or something to load them, if they are not in the user’s cache already.
This is true, and there are already some meatures in place. For example, the “Over data / Over WiFi” settings. If those are not set to “always”, then the screenshots must be clicked to be downloaded. Plus once the icon.png SHA-256 naming in Graphic hash filename for caching (!669) · Merge requests · F-Droid / fdroidserver · GitLab is proven, we can apply that to the screenshots as well.
One thing that will keep the website responsive in browsers when the site is running slow is using the jekyll-assets plugin to set unique, hash-based file names for all of the assets in the website, e.g. CSS, JS, website images, etc. Then files matching that pattern can be set to cache forever. I don’t think it’ll help much with load though, since mostly those files are small, but maybe.
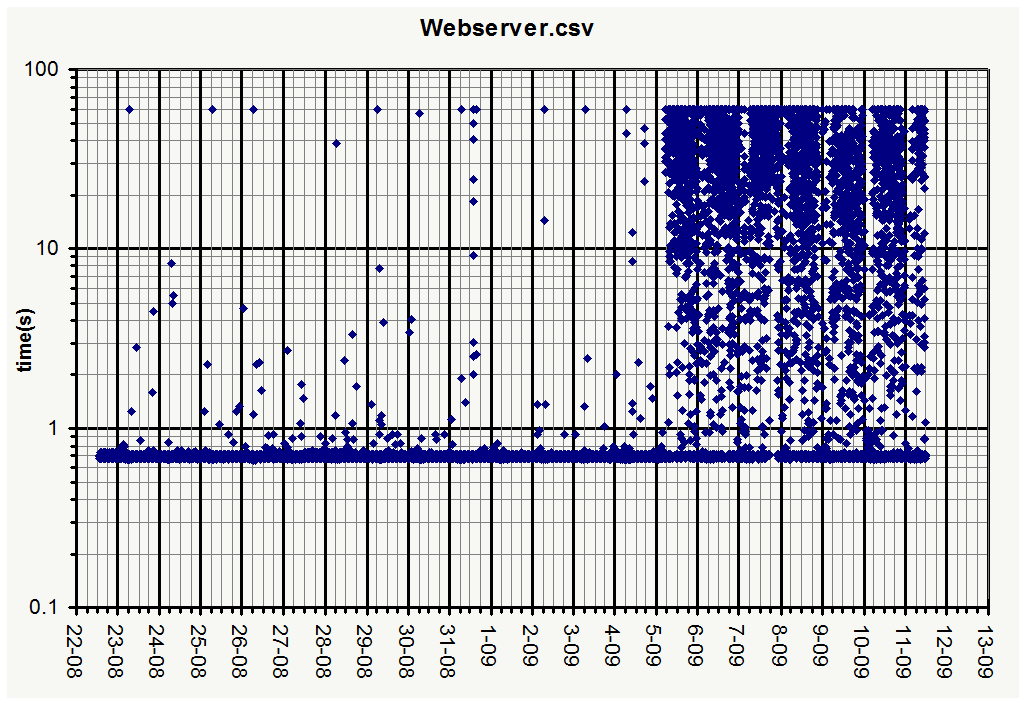
would your script allow to plot the data points with transparency (maybe 25% or so in the alpha channel) so that overlapping data points would appear darker?
(Seems to me that Sep,4th and Aug,21st were the most favorable days)
This pattern makes me think that the webserver is running out of threads to serve the requests. Right now, the uptime load numbers are 0.75, 0.63, 0.62, the CPU is at about 5% and the RAM usage is almost all caching:
A lot of file caching. I am thinking maybe the new proxy is not actually caching, just passing through all requests? Do you have mod_status running there? That would be helpfull.
Otherwise “apachectl status” may give you a simple status output via systemd. Like mine says:
If these load spikes correspond to repo updates then you are correct that most of the traffic is from apk updates by the android client app.
Adding mirrors reduces the load, but the best way to protect the website is to split repo and website in physically separated servers, exactly like you have done for staging.f-droid.org. It is using another repo mirror that is often more responsive than the primary one. Would be great if it could switch mirrors if the current one is unresponsive, like the android client does, either manual or automated.
About my proxy server, maybe it is best to turn it into a repo mirror.
Hetzner allows 20TB/month of traffic with their cheap 3 euro VPS. That averages 682 GB/day and is comparable to what fau.de is serving. If not enough, just spawn another and add it to round-robin dns.
The only problem with those VPS’s, they do not have the storage to hold the entire repo unless you buy extra. But when configured as a proxy instead of an rsync mirror, it will automagically hold the most popular downloads. The bulk of the repo is older versions that very few people download. I think that gives the most bang for the buck.
@hans root on webserver should not be needed - you can run /usr/sbin/apache2ctl status as regular user if webserver is configured to allow it (or any altenative to apache2ctl status like lynx http://localhost:80/server-status, or wget -q -O status.html http://localhost:80/server-status or curl http://localhost:80/server-status etc).
It would be very interesting output to see if you can get it.
If it is MaxRequestWorkers issue, you’ll see few threads in “_” or “.” (available) states.
If apache is using KeepAlive on, it could easily be KeepAlive thing (you’ll see lots of threads in “K” state), which could be fixed by lowering to KeepAliveTimeout 5 (or even lower, like 2). Many “L” would indicate excessive logging (or at least need to set BufferedLogs On), “R”/“W”/“C” might indicate network issues (bandwidth or packet loss) etc.







{kind=link}
{kind=link}