I ran your timing script on a server in Oregon. It runs against the two caching servers, and the webservers. The data is attached here:
Could you make your nice graphs out of those?
I ran your timing script on a server in Oregon. It runs against the two caching servers, and the webservers. The data is attached here:
Could you make your nice graphs out of those?
Unfortunately the files you posted are a bit messed up because we have different locales on our systems and the ‘time’ command behaves differently.
On US locale it outputs floating point numbers and in (I guess) DE locale it outputs floating comma. On yours it also echos the curl commandline.
This modified version may work better: #!/bin/bashexport LC_ALL=en_US.UTF-8FILE="/mnt/data/temp/timelog.csv"CMD=" - Pastebin.com
But dont worry, the information is in there, just need to apply some text filtering. I am working on it.
Edit: Here they are!
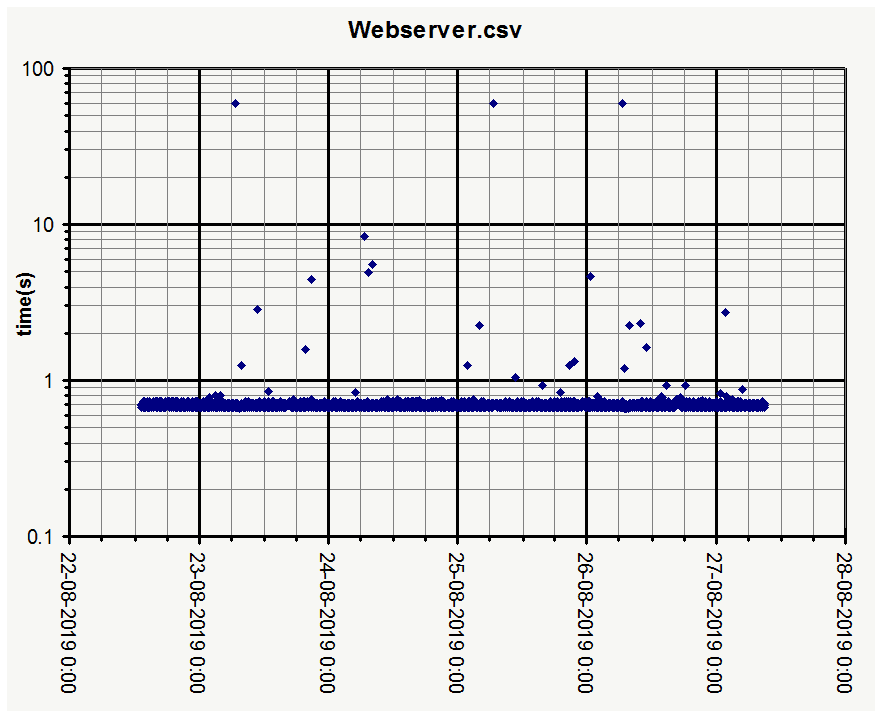
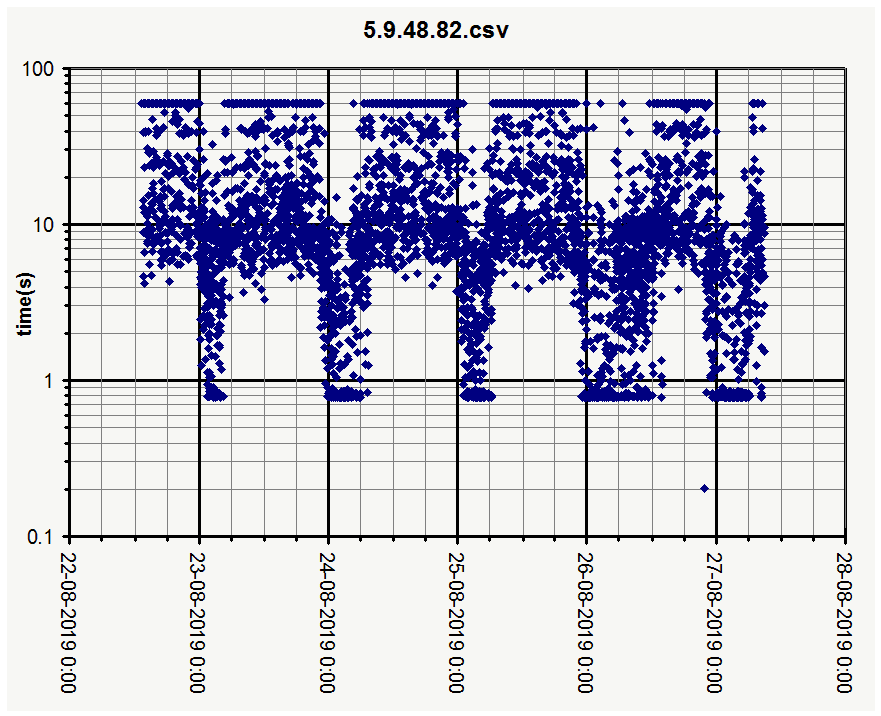
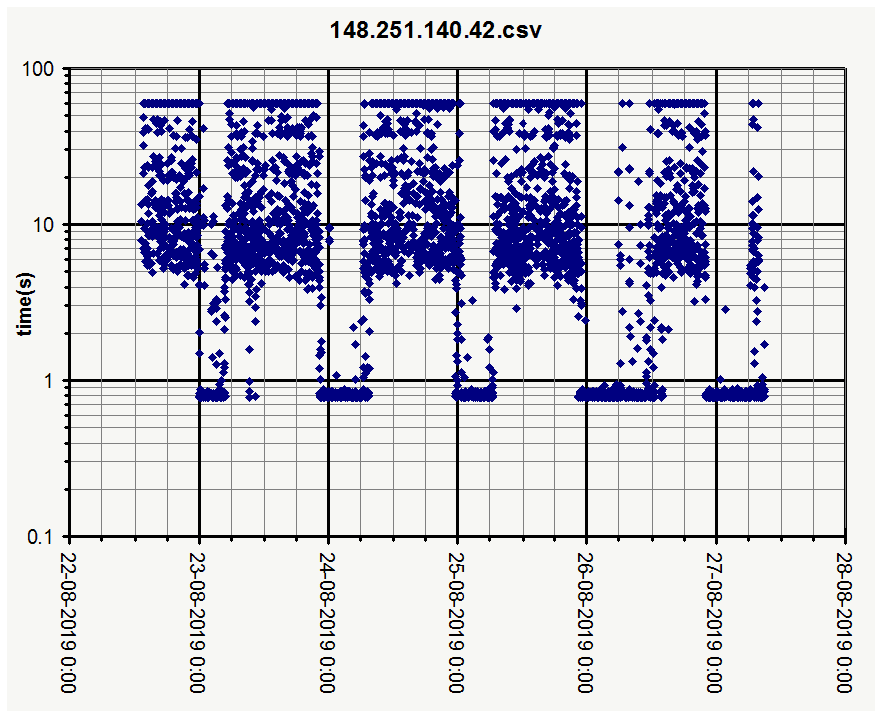
The banding pattern from my first charts is not very visible in yours, maybe that is because ping times are longer. I seem to be very close to the server in terms of network delays.
The single dot in the 5.9.48.82 graph at 0.2s is a curl error 7: “Failed to connect() to host or proxy.”
All three show the same kind of delays, only “Webserver” much less, likely due to much lower traffic volume.
To find the cause of the delays someone should log into one of the proxies and do some detective work. There is not enough traffic on the main server to do it there. If this is not possible than we need to set up another proxy as you suggested. I could do that.
Only @CiaranG has access to those proxies, and these days, he’s rarely available for this kind of thing.
If these are private servers it makes perfect sense he is not sharing accounts, but IMHO f-droid should have at least one proxy under full control. This means at least two people with sudo power and one actively maintaining it.
With your permission I will register and get the € 3.01 VPS from Hetzner, create two accounts and we’ll see what we can do with it. That’ll be my contribution to f-droid.
I have seen the immutable property in action, that is great! Thanks for your efforts. When hitting F5 (not shift-F5 that forces full reload) the images and other resources are loading in 25-150 microseconds from cache on my pc. The one slow resource request appeared to be a bug that results in “500 Internal Server Error”:
Some packages listed in | F-Droid - Free and Open Source Android App Repository (like /d/gapps and Addi) have no icon associated and this results in a broken image URL pointing to F-Droid while it probably should point to a default icon like https://f-droid.org/assets/ic_repo_app_default.png
Another round of profiling data, which should also cover the roll out of the new cache settings:
I updated my copy of the script with your changes. Sorry, those files I just posted are still the old format, hopefully you still have your script to clean them up.
Also, I’ve started asking @CiaranG to add another caching instance. I already have sponsored VMs from a trusted host for the official one. Maybe it is worthwhile to have you setup another caching webserver for staging.f-droid.org? Then we can have a full copy of the setup to test with.
I found it in the command history:
cat webserver.csv|perl -pe 's/\+\+.*\n//'| sed 's/,/./2' > webserver_fixed.csv
Ok I will get a VPS then ![]()
if you need some hosting ping me
Disclaimer: I dislike referring to big G, but sometimes even the devil may have useful info’, and torbrowser (noscript) helps you get there. Anyway, it may have some useful insights.
https://www.wmtips.com/tools/info/?url=f-droid.org
https://developers.google.com/speed/pagespeed/insights/?url=https%3A%2F%2Ff-droid.org%2F&tab=desktop
With both desktop and mobile results…
f-droid has a preference for png images, which could be significantly smaller with other formats. The time savings varies.
Webfonts, /assets/roboto.ttf is shown with potential 1.6 second (!) potential savings.
It does appear the cache time of mostly 12 hours or “none” should be increased.
The Critical Request Chains below show you what resources are loaded with a high priority. Consider reducing the length of chains, reducing the download size of resources, or deferring the download of unnecessary resources to improve page load. Learn more.
Maximum critical path latency: 3,790 ms
Initial Navigation
/assets/roboto.ttf(f-droid.org)
To set budgets for the quantity and size of page resources, add a budget.json file…
Problem is that all resources have a variable latency, probably due to high server load.
Caching of images and other resources has been improved but can be improved further.
The png format can be, depending on content, more efficient than jpeg. I don’t think anyone wants to get ugly jpeg’s to save a few bytes, but perhaps some png’s can be compressed more efficiently. Most (if not all?) are in 32bpp while many can do fine with a somewhat smaller 8bpp.
Anyway, if you improve the above, the gain is not huge and it is not likely to fix the delay problem completely.
I made a caching proxy using nginx, connected to the staging server.
https://static.21.207.203.116.clients.your-server.de/
Running on Fedora 29 - the devil I know.
I have been reading up on proxies and web accelerators:
Edit:
Tweaked the SSL configuration to balance compatibility, performance and security.
Using both EC and RSA certificates. HTTP2, TLSv1.3 speed things up a little. Supports Android 2.3.7 while avoiding insecure ciphers.
https://www.ssllabs.com/ssltest/analyze.html?d=static.21.207.203.116.clients.your-server.de&hideResults=on
I think nginx makes sense for this. Your site seems to work fine, the only issue I found is that the wiki is 403:
What would be really nice would be to have this caching server setup in Ansible in a git repo. That’s what we’ve been doing for all new server setups recently, for example:
Also, FYI, we use Debian for everything. But its fine to keep the prototype in whatever. It should be easily portable to Debian/buster.
It mirrors the staging server and that is also 403.
The images in staging are on fau.de and wont be cached by nginx. Maybe I should switch to mirroring the current proxies via http://f-droid.org/ for a more realistic test?
Thanks for the gitlab links. I was planning to create an install script and put that in a repo. Fedora/debian differences can be solved with a couple IF’s. I can test for both.
Ansible is all new for me and a steep learning curve. Perhaps someone could assist with that in due time, but maybe for now I could stick with a Bash script? It is not a whole lot it has to do, just install nginx, slap a config file on it, create a few dirs and get a certificate.
I agree, I think for now it makes sense to start with f-droid.org to
test all the aspects of the website.
A bash script is fine for me, I can convert it to Ansible as needed.
Some issues:
curl -IsS https://staging.f-droid.org/assets/favicon.ico
And he did. IP = 107.150.51.2.
Uptime guess: 2.652 days (since Tue Sep 3 23:03:17 2019)
Maybe that is why we saw a little improvement, some load was taken off the others.
Unfortunately it also has the same slow response times as the others.
is your caching server pointing to f-droid.org now? It would be
interesting to see if it follows the same slowdown periods.
Yes it is.
Points 1) and 4) above are are mitigated by performing a search&replace in mid-flight html:
sub_filter_once off;
sub_filter 'https://$proxy_host/' 'https://$server_name/';
sub_filter 'img class="package-icon" src="https://$proxy_host/repo/"'
'img class="package-icon" src="/assets/ic_repo_app_default.png"';
The proxy is slow when it is waiting for content form the origin server so I tried to improve the caching, Point 3). A config snippet:
map $request_uri $max_age {
default 600; # 10 min default (for html)
~^/assets/ 43200; # 12 hours for website assets
~^/js/ 43200;
~^/css/ 43200;
~^/FDroid.apk 86400; # 1 day for the F-Droid apk
~^/repo/icons-\d*/ 604800; # 1 week for repo files with version number in name
~^/repo/.*\.apk$ 604800;
~^/repo/.*\.apk.asc$ 604800;
~^/repo/.*\.tar.gz$ 604800;
~^/repo/.*/icon.png$ 86400; # 1 day for icons and screenshots without version number
~^/repo/.*/phoneScreenshots/ 86400;
}
Then in ‘location’ section:
add_header Cache-Control “max-age=$max_age, public, immutable”;
Point 2) appears to be severe. Not just the icons grow to 512x512 because google wants that for the playstore, but also the screenshots get much bigger because people have bigger phones. I have run a few tests to heavily optimise some PNG’s and it turns out many can be shrunk by more than 10x in file size while maintaining display quality. This could be a massive bandwidth saver!
{kind=link}
{kind=link}