I have been experiencing problems with the f-droid.org webserver for a long time now, in particular icons not loading in the app or only after a long time.
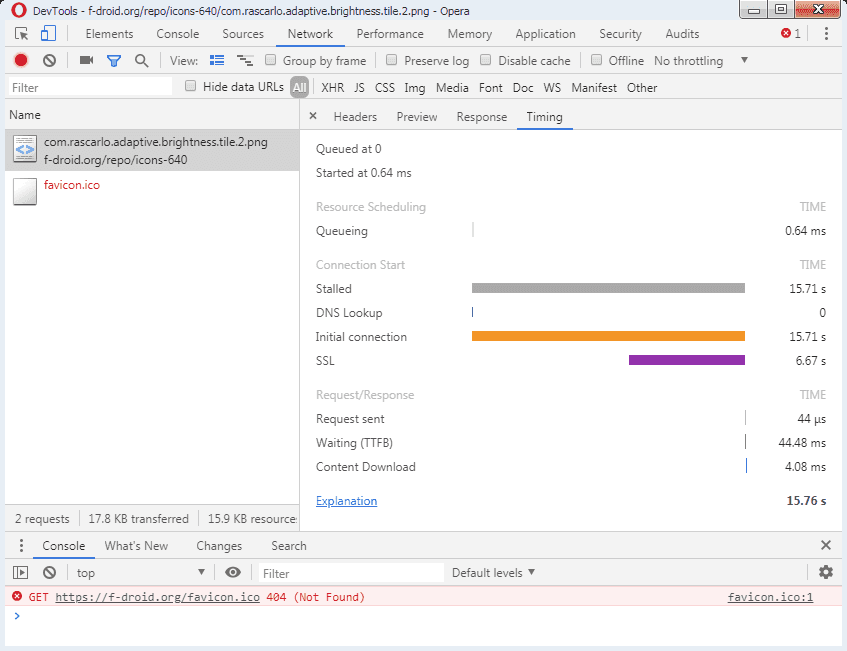
I did a little test, requesting only one little icon in my webbrowser, screenshot:
Just creating the initial connection took more than 15 seconds. Sending the data itself is lightning fast, 4ms.
Sometimes it takes so long that the browser just times out, but download speeds are good once a request is being served.
This looks like there are not enough request workers to handle all connections. Many users may be downloading large files through their slow internet connections, keeping workers occupied and everyone else must just wait in line to get served.
From Apache docs:
The [MaxRequestWorkers](https://httpd.apache.org/docs/2.4/mod/mpm_common.html#maxrequestworkers) directive sets the limit on the number of simultaneous requests that will be served. Any connection attempts over the MaxRequestWorkers limit will normally be queued, up to a number based on the ListenBacklog directive. Once a child process is freed at the end of a different request, the connection will then be serviced.
Perhaps you have already tuned this and there is some DDoS going on? Monitoring the server with mod_status may provide some clues.
Then there is Cache-Control: immutable which can make a big difference in the number of connections the server needs to process. The icons are just static content so why not make better use of client caching? This directive may also pave the way for mirroring with caching reverse proxies.
Thanks for this profiling info, its really valuable! I’ll monitor the webserver to see if more workers would help. Its actually using the mpm “event” mode with these settings:
About improving the caching, we welcome merge requests on F-Droid / Website · GitLab. The site could easily use forever caching if someone made it so that jekyll added hashes to each filename for each image. Same goes for .js and .css files.
Thanks for the reply. Tomorrow I will try some more analysis and investigate if SSL may play a role in the delays. We’ll get to the bottom of this!
I wonder what the cpu load is and if it is evenly distributed across all available cores.
Can you try command “mpstat -P ALL 1 10” on the server to check CPU load for individual cores? This will give you 10 measurements at 1 second interval plus an average value. You may need to install package “sysstat” for this.
most of the time, the server is just coasting. It is only when the
updates get published that there is a load spike. So troubleshooting
can only happen then.
The problem is always there, not just during load spikes. In fact I cannot remember a single time when delays did not occur, though the severity varies. So lets troubleshoot some more:
Testing f-droid.org at SSL Server Test (Powered by Qualys SSL Labs) fails completely on both IP’s with
“unable to connect to server”. This is very strange. I notice they are both hosted at Hetzner. Are they really two physically separated hosts?
Ping to both IP’s gave me a very consistent and perfect score, no loss and all below 20ms.
Then testing without SSL, just plain HTTP:
$ time curl --connect-to 148.251.140.42 -v http://f-droid.org/
$ time curl --connect-to 5.9.48.82 -v http://f-droid.org/
Got the “301 Moved permanently” responses within half a second, often well below 100ms. Good.
Then with HTTPS:
$ time curl --connect-to 148.251.140.42 -v --output /dev/null https://f-droid.org/
$ time curl --connect-to 5.9.48.82 -v --output /dev/null https://f-droid.org/
With several attempts, gave me 4.5 to 16s delay or made me hit CTRL-C after some 2 minutes.
The verbose output indicates that the delays occur mainly before any SSL negotiation takes place.
Is the delay within the servers or somewhere in between me and the servers?
You may provide the answer by trying on one of the hosts:
$ time curl --connect-to localhost -v http://f-droid.org/
On my server this takes 38ms while using the same cipher as f-droid.org (ECDHE-RSA-AES128-GCM-SHA256)
If you get the long delays I am curious what the cpu loads tell us.
Some more thoughts:
It would not really surprise me if Hetzner gave SSL packets some sort of “special treatment” in one of their faulty routers. A friend of mine had connection problems for ages with these guys until they replaced a router after many complaints.
It could also be a bug. I experienced long delays with SSH connections on my own LAN with an idle server. A reboot always resolved it until it came back again at some random moment to haunt me. I have not seen it for a while though, maybe some kernel or ssl update fixed it.
There are two caching proxies on those two public IP addresses. They act as reverse proxies to the actual webserver, which is not public. The response time of the public caches depends on what is cached, and how slow the webserver is running. I think the 301 comes from the caching proxy, so it’ll always be fast.
Running time curl --connect-to 5.9.48.82 -v --output /dev/null https://f-droid.org/ right now for both IPs gives me currently a time range of 1-3 seconds. Doing the same thing from the deployserver to the webserver (both not public machines) gives me responses of about 0.25 seconds each time.
I don’t have shell access to the caching proxies so I can’t measure from there.
Thank you Hans.
I have made a mistake with curl, the option “–connect-to” has no effect the way I used it. My apologies, I should have verified the output. We should use the “–resolve” option instead.
Something has changed. The SSLlabs test SUCCEEDS with a perfect A+ rating for the IP 148.251.140.42. That is GREAT!
(I think you get the “+” because Strict Transport Security (HSTS) is configured).
The command time curl -v --output /dev/null https://f-droid.org/ --resolve f-droid.org:443:148.251.140.42
gives me consistently a speedy 0.138s from my location (The Netherlands)
The other IP 5.9.48.82 is still problematic, the SSLlabs test fails after nearly 500 seconds and curl takes some 5-20, once even 70 seconds.
That means the problem is in the proxies. If someone has done something to one proxy, then thank you and please do the same thing to the other.
Possibly.
Or perhaps a simple reboot solved the problems: # nmap -O -v -p 80 148.251.140.42 | grep -i uptime
Uptime guess: 1.852 days (since Wed Aug 14 14:41:16 2019) # nmap -O -v -p 80 5.9.48.82 | grep -i uptime
Uptime guess: 1.049 days (since Thu Aug 15 09:58:37 2019)
(note that only port 80 is scanned here, that is not rude I suppose)
The F-droid app is at this moment blissfully fast and smooth compared to what it was, but I do get a few slow responses from 5.9.48.82 so now and then.
DDoS is still a possiblility. Did you get any useful info from mod_status?
Those boxes are most likely Xen VMs, so the kernel is updated without rebooting guest instances. The load does seem to reliably follow index updates, so I think this issue is most likely to be related to that. But that is something to test. Could you run your tests on a schedule? Then we can compare that to the schedule of the index updates.
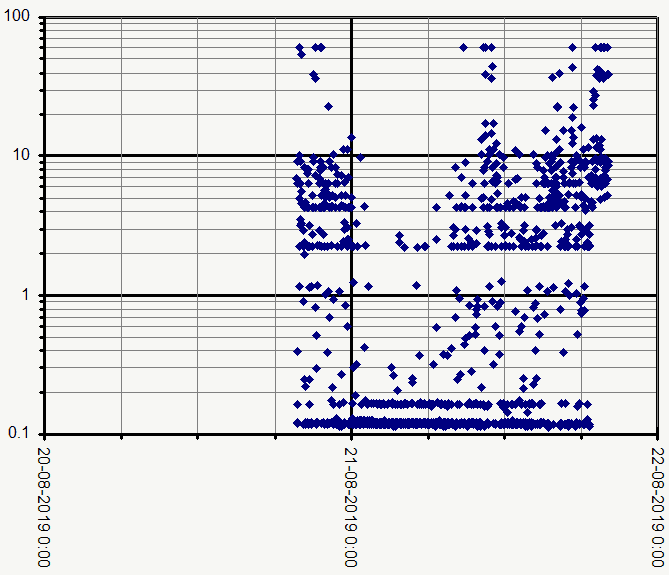
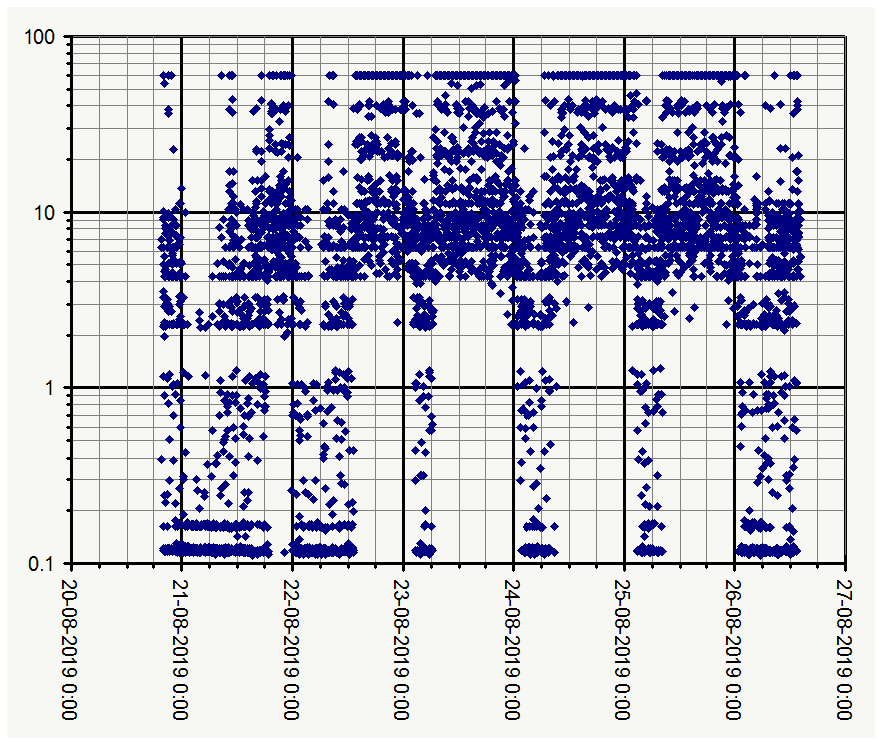
I crafted a simple script to schedule the test and plotted the response time in seconds for fetching the tiny favicon from 5.9.48.82. Timeout is set to 60s. It has been running for about a day now.
The results are weird and I am not sure what to make of it. Just some thoughts:
Certain response times are much more common than others. It looks like there is a threshold effect caused by something that hits a certain limit. I know it sounds vague, I am just guessing and speculating. We could be looking at a server misconfiguration, an underpowered VM acting up or perhaps other things are running on the VM that eat resources? I probed a couple other nearby IP’s for https services and those are very vast, probably just idling. It does not look like a general ISP issue.
But no matter what the cause, this should not be happening in the first place. It has been going on for a very long time. Apparently nobody is monitoring those two proxies and carefully tuning its performance. The caches report “Server: Apache” in their http response headers and just a quick google search reveals there are better options available.
Since I got a nearly google free phone I depend on F-droid for many apps and I would like to see things improve. My home server has only 30Mbit/sec upload, not fast enough for a cache or mirror I guess, but I am thinking VM’s are cheap and perhaps I could get one to tinker with. Please let me know if I could be of any help.
Nice plot! Looks like the majority of those are very fast. It will be interesting to see it going through the whole release cycles to see if clear patterns emerge.
We have been monitoring this and know at least one promising solution: replacing the wiki with static files and switching fully to a CDN model for hosting. That requires a chunk of work, so that’s the most effective place to contribute right now. That mostly means replacing the code in fdroidserver that posts build updates to the wiki and making it instead post static files, e.g. build logs.
Also, another thing that someone could take on as a project is improving the website caching. That is a clear win no matter what the server configuration is.
I fully agree with improving the caching. Unfortunately I am not much of a programmer so I would hesitate to contribute to the F-droid sources, but I have some experience managing Linux (fedora) servers. Perhaps I can contribute with the caching stuff and read up on CDN.
Some thoughts about that:
I dont think we need geographically distributed caches at this point, but we do need enough capacity. Currently the delays are mostly in the servers, not much in the transit over the internet.
Cache-Control: immutable can be implemented for static content without changing anything else.
When a client supporting immutable sees this attribute it should assume that the resource, if unexpired, is unchanged on the server and therefore should not send a conditional revalidation for it (e.g. If-None-Match or If-Modified-Since) to check for updates.
Current configuration for the favicon is “Cache-Control: max-age=43200, public”, that is 12 hours expiration time. To get started, we could bump the expiration to 24h and apply ‘immutable’ only to images. Getting an outdated image would be relatively harmless I suppose. Something like <filesMatch ".(png|jpg)$"> Header set Cache-Control "public, max-age=86400, immutable" </filesMatch>
Then monitor the effect on the servers. Later we could add other types like css, js and eventually the actual apk downloads.
The Hetzner VPS may be very resource limited, they are cheap and you get what you pay for I suppose. Unless someone provides the cash for a more powerful solution, we can only get more performance with careful tuning. I could get a VPS and see what I can do if you think that is a good idea.
Cache-Control: immutable sounds like the best quick solution. I temporarily enabled it on f-droid.org, until the next website auto-deploy. That should give us about a day to test.
Thanks for the quick action.
The f-droid app displays the images instantly if they were loaded in a previous session.
But with my desktop browser I dont see the immutable property anywhere.
(tested with Opera/Chrome Devtools, click network tab then force reload the page with shift-F5)
I just found a bug in the HTML caching: the pattern is *.html but the actual files include the locale in them, e.g. index.html.en, index.html.zh_hans. So they were not getting Cache-Control headers.
Since it looks like the webserver is far from overloaded, so the issue must either be in the caching front-facing servers, or the interaction between those and the webserver. I think it would be worthwhile, if you are still up for it, to set up an Apache reverse proxy caching webserver and see how that performs.